
































































- Blockchain Council
- November 09, 2023
- In today’s digital age, fraud detection is crucial due to the increasing use of technology in our lives.
- This article dives deep into fraud detection using machine learning.
- Machine learning is essential for fraud detection, using data, algorithms, and automation to identify and prevent fraudulent activities effectively.
- The digital age has brought convenience but also increased the risk of fraud, costing billions of dollars globally.
- Traditional fraud detection methods are outdated and struggle to keep up with evolving fraud tactics.
- Machine learning excels at analyzing data, distinguishing between genuine and fraudulent activities, and adapting to new threats.
- Fraud takes various forms, including identity theft, credit card fraud, investment scams, insurance fraud, and cybercrime.
- Understanding the difference between insider and outsider fraud is crucial for prevention and detection.
- Data preprocessing is vital for fraud detection, involving data cleaning, handling imbalanced datasets, and feature engineering.
- Supervised and unsupervised learning approaches, along with deep learning and neural networks, are used in fraud detection.
- Real-time fraud detection is essential, and emerging technologies like AI, blockchain, and IoT will shape the future of fraud prevention while addressing ethical and privacy concerns.
Introduction
In today’s digital age, where technology permeates every facet of our lives, the importance of robust fraud detection has surged to unprecedented levels. As our transactions, interactions, and communications increasingly migrate to the virtual realm, fraudsters have seized new opportunities to deceive and defraud individuals and organizations alike.
This evolution has necessitated a corresponding transformation in our approach to fraud detection. Traditional methods, once deemed sufficient, have proven inadequate in safeguarding against the ever-adapting tactics of cybercriminals. It is in this context that machine learning emerges as a powerful and indispensable tool, revolutionizing the field of fraud detection by leveraging the prowess of data, algorithms, and automation to identify and thwart fraudulent activities with unprecedented accuracy and efficiency. In this article, we will discuss how machine learning can help in fraud detection.

The Growing Importance of Fraud Detection in the Digital Age
The digital age has ushered in an era of unparalleled convenience and connectivity, enabling seamless transactions, global commerce, and instant communication. However, it has also opened Pandora’s box, providing malicious actors with a vast playground to exploit vulnerabilities for personal gain. The global cost of digital ad fraud in 2023 alone is around $100 billion.
As financial transactions, sensitive data, and personal information traverse the digital landscape, the risk of fraud looms large. The repercussions of fraud extend beyond financial losses to encompass profound societal and reputational impacts, eroding trust and undermining the very fabric of our digital society. Hence, the need for effective fraud detection has become not just a matter of financial prudence but a critical imperative for preserving the integrity of our digital ecosystems.
Also Read: How To Use Google Bard?
The Limitations of Traditional Fraud Detection Methods
Traditional fraud detection methods, rooted in static rule-based systems and simplistic algorithms, have struggled to keep pace with the rapidly evolving tactics of fraudsters. These conventional approaches are ill-equipped to adapt to the ever-changing nature of fraud, resulting in a cat-and-mouse game where fraudsters stay one step ahead. Rule-based systems, while providing a rudimentary level of protection, are rigid and incapable of learning from new patterns or data. Furthermore, these methods often generate a high volume of false positives, inundating investigators with alerts, and diverting resources away from genuine threats. The limitations of traditional fraud detection systems underscore the urgent need for a paradigm shift, one that harnesses the potential of machine learning to not only detect fraud but also predict and prevent it.
The Role of Machine Learning in Enhancing Fraud Detection
Machine learning, with its ability to analyze vast datasets, identify intricate patterns, and adapt in real time, has emerged as a game-changer in the arena of fraud detection. By leveraging advanced algorithms, machine learning models can scrutinize transactions, behaviors, and anomalies with unparalleled precision. They can distinguish between genuine activities and fraudulent ones, even when fraudsters employ sophisticated tactics to mask their intentions. Machine learning models excel at uncovering hidden patterns and outliers, making them ideal for identifying previously unseen fraudulent schemes.
Moreover, they evolve and improve over time, learning from new data and adapting to emerging threats. This dynamic and data-driven approach to fraud detection not only enhances accuracy but also reduces false positives, streamlining the investigative process and allowing organizations to focus resources where they are most needed.
Also Read: How IoT Is Changing Various Industries
Understanding Fraud and Its Types
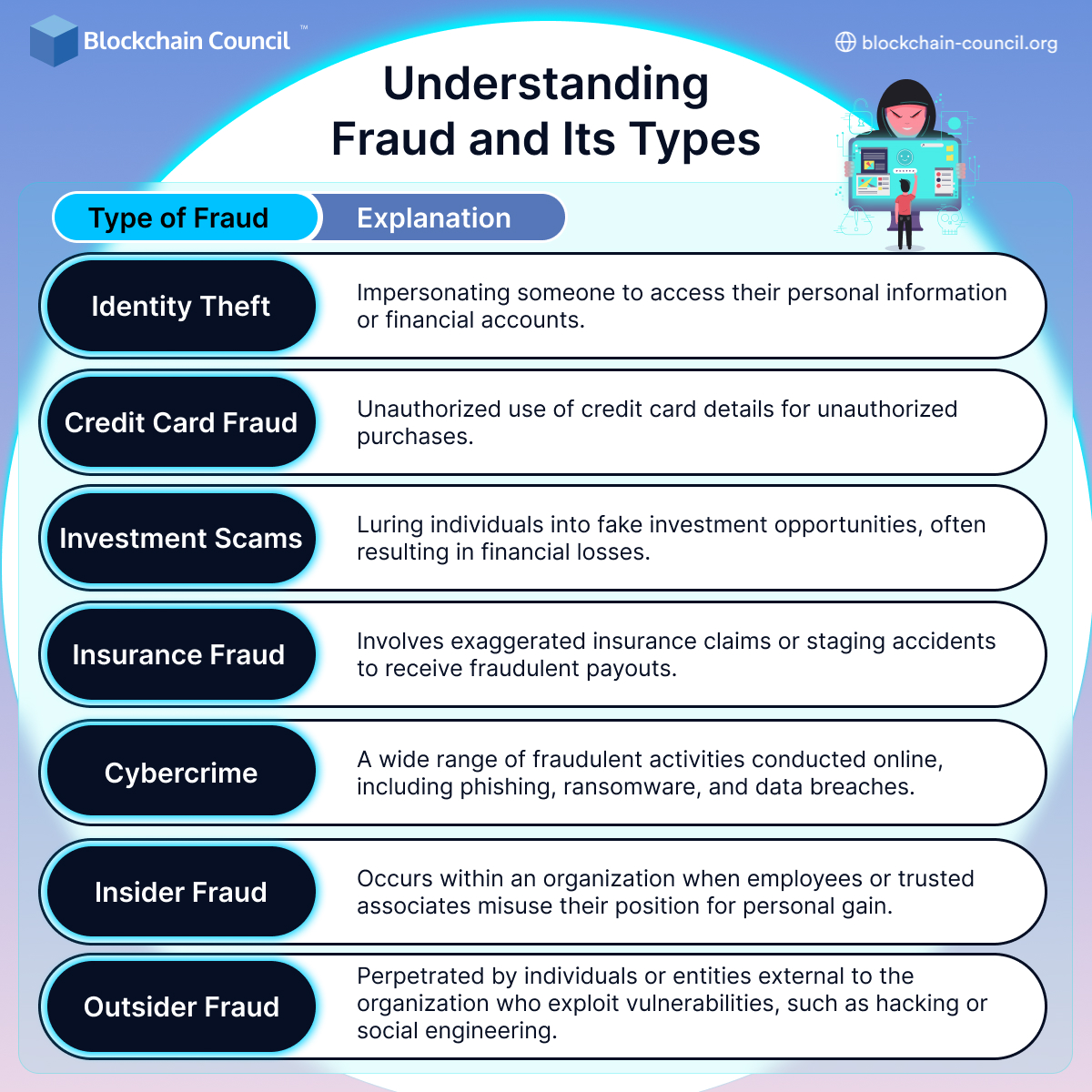
Fraud is a deceptive act committed to gain an unfair or unlawful advantage, typically involving deceit, misrepresentation, or concealment of information for personal or financial gain. It can take various forms, each with its unique characteristics and implications. Fraudulent activities can range from simple deceptions to complex schemes that exploit vulnerabilities in systems and human trust.
- Fraud manifests in several ways, including but not limited to identity theft, credit card fraud, investment scams, insurance fraud, and cybercrime. Identity theft involves impersonating someone to access their personal information or financial accounts.
- Credit card fraud entails unauthorized use of credit card details for unauthorized purchases. Investment scams lure individuals into fake investment opportunities, while insurance fraud can involve exaggerated claims or staged accidents. Cybercrime encompasses a wide range of fraudulent activities conducted online, such as phishing, ransomware attacks, and data breaches.
- The consequences of fraud are far-reaching, affecting individuals, organizations, and society as a whole. Financially, it can result in substantial losses for victims and businesses, eroding trust in financial institutions. Societally, fraud undermines confidence in systems, leading to increased regulations and costs for consumers. Additionally, the reputational damage inflicted on both individuals and organizations can be long-lasting, impacting their credibility and trustworthiness.
- One critical aspect of understanding fraud is distinguishing between insider and outsider fraud. Insider fraud occurs when individuals within an organization, such as employees or trusted associates, misuse their position for personal gain. They often have access to sensitive information, making them adept at concealing their activities. In contrast, outsider fraud is perpetrated by individuals or entities external to the organization. They may employ various tactics to exploit vulnerabilities, such as hacking into systems, creating counterfeit documents, or engaging in social engineering.
- Fraud encompasses a wide range of deceptive activities aimed at personal or financial gain through deceit and misrepresentation. Its various forms can have significant financial, societal, and reputational impacts. Distinguishing between insider and outsider fraud is crucial for effective prevention and detection. To combat fraud effectively, individuals and organizations must remain vigilant, adopt robust security measures, and promote a culture of ethical behavior and transparency.
Data Preprocessing for Fraud Detection
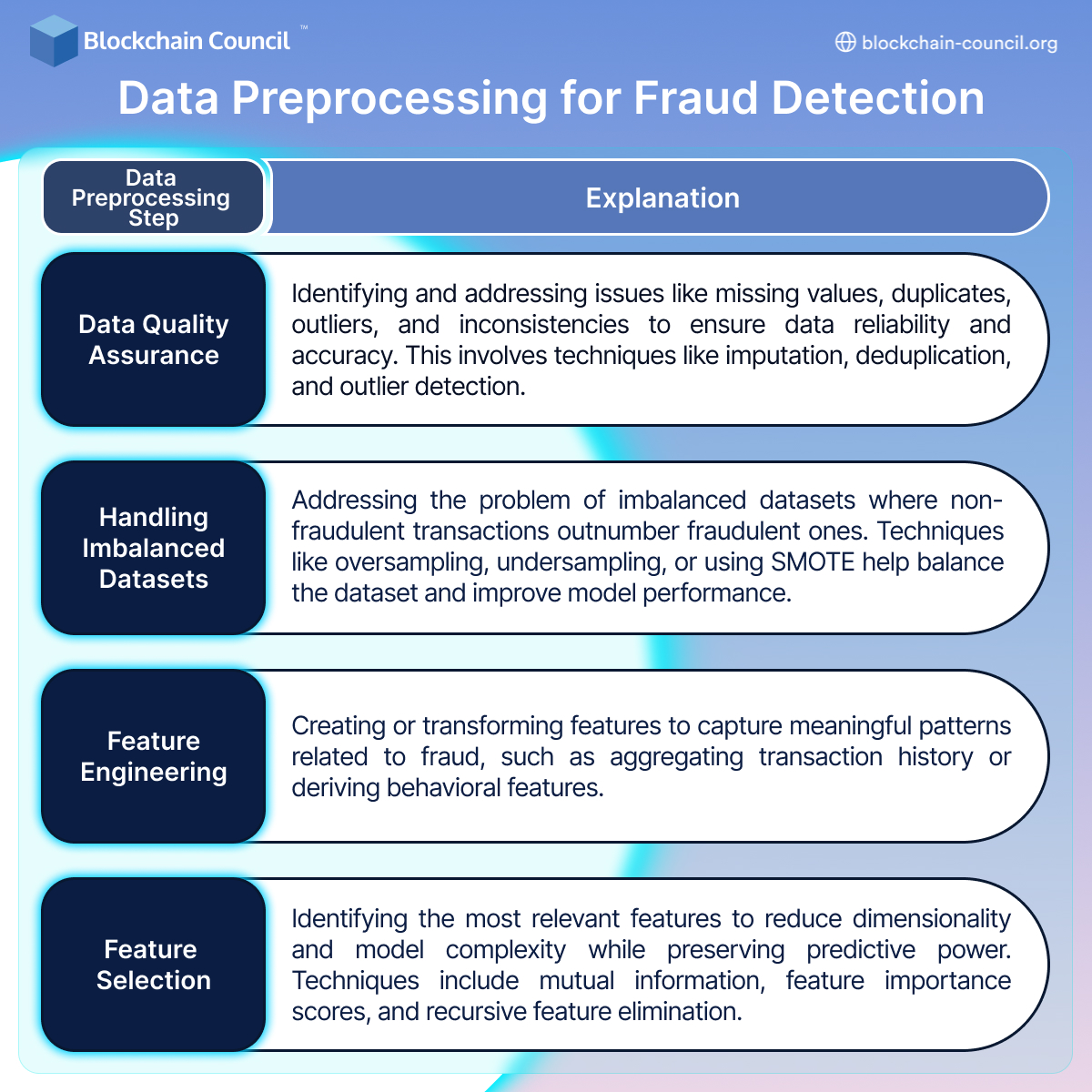
Data preprocessing plays a pivotal role in the success of fraud detection models. It involves a series of steps to clean, transform, and prepare the data before feeding it into machine learning algorithms. The quality of data and the techniques applied during preprocessing significantly impact the accuracy and effectiveness of fraud detection systems.
- First and foremost, data quality is of paramount importance. Inaccurate or incomplete data can lead to false positives or negatives in fraud detection, potentially causing financial losses and damaging a system’s reputation. Data quality assurance involves identifying and addressing issues like missing values, duplicates, outliers, and inconsistencies. It often requires data cleansing techniques such as imputation, deduplication, and outlier detection to ensure that the data is reliable and accurate.
- Handling imbalanced datasets is another critical aspect of data preprocessing in fraud detection. Imbalanced datasets occur when the number of non-fraudulent transactions far outweighs the number of fraudulent ones. If not addressed, models trained on such datasets may become biased towards the majority class, making it challenging to detect fraud accurately. Techniques like oversampling the minority class, undersampling the majority class, or using synthetic data generation methods like SMOTE (Synthetic Minority Over-sampling Technique) help balance the dataset and improve model performance.
- Feature engineering and selection are also vital steps in data preprocessing for fraud detection models. Feature engineering involves creating new features or transforming existing ones to capture meaningful patterns related to fraud. This can include aggregating transaction history, calculating transaction frequency, or deriving behavioral features. Feature selection, on the other hand, involves identifying the most relevant features to reduce dimensionality and model complexity while preserving predictive power. Techniques like mutual information, feature importance scores, or recursive feature elimination help in selecting the most informative features for fraud detection.
- Data preprocessing is a crucial phase in building effective fraud detection models. Ensuring data quality, addressing class imbalance, and performing feature engineering and selection are essential steps to enhance the accuracy and reliability of these systems. Properly preprocessed data not only improves fraud detection but also reduces false alarms, making the detection process more efficient and cost-effective. Fraud detection is an ever-evolving field, and continuous refinement of data preprocessing techniques is essential to stay ahead of evolving fraud tactics.
Also Read: What Is Google Bard And How Does It Work?
Supervised Learning Approaches
Supervised machine learning is a powerful technique employed in fraud detection, where models are trained using labeled data to make predictions or classifications. This approach is particularly effective because it leverages historical data with known outcomes to teach the model to recognize fraudulent activities. Several algorithms are commonly used in supervised learning for fraud detection, including Logistic Regression, Decision Trees, and Random Forests.
- Logistic Regression is a linear classification algorithm that’s often used as a baseline model in fraud detection. It’s suitable for binary classification problems, making it well-suited for distinguishing between legitimate and fraudulent transactions. Logistic Regression estimates the probability of an event occurring and can provide insights into which features contribute most to the classification.
- Decision Trees are non-linear models that can handle both binary and multi-class classification tasks. They create a tree-like structure of decisions based on the features of the data. In the context of fraud detection, decision trees can help identify key factors leading to fraudulent transactions. However, they can be prone to overfitting, which is where they perform well on training data but poorly on new, unseen data.
- Random Forests address the overfitting issue of decision trees by combining multiple trees into an ensemble model. Each tree in the forest makes a prediction, and the final classification is determined by a majority vote or averaging of the predictions. Random Forests are robust and can handle imbalanced datasets, making them a popular choice for fraud detection tasks.
- Model evaluation and performance metrics are crucial for assessing the effectiveness of supervised learning models in fraud detection. Common metrics include ROC AUC (Receiver Operating Characteristic Area Under the Curve), which measures the model’s ability to discriminate between fraud and non-fraud cases across different thresholds. A higher ROC AUC indicates better discrimination. The F1 Score combines precision and recall, providing a balanced measure of model performance. Precision measures the ratio of true positives to the total predicted positives, while recall measures the ratio of true positives to the total actual positives.
- Supervised learning approaches like Logistic Regression, Decision Trees, and Random Forests are valuable tools in fraud detection. They leverage labeled data to train models capable of identifying fraudulent activities. Proper evaluation using performance metrics like ROC AUC and F1 Score is essential to ensure the models are effective in identifying fraud while minimizing false alarms. Continuous monitoring and improvement of these models are crucial as fraud tactics evolve over time.
Unsupervised Learning Approaches
Unsupervised learning is a valuable approach in fraud detection that doesn’t rely on labeled data but instead aims to identify patterns and anomalies within the data itself. This is particularly useful when dealing with evolving and unknown fraud patterns. Unsupervised learning techniques include clustering methods like K-Means and DBSCAN for anomaly detection, as well as algorithms like Isolation Forests and One-Class SVMs for outlier detection.
- Clustering methods such as K-Means and DBSCAN are widely used in unsupervised fraud detection. K-Means groups similar data points into clusters based on their features, with the assumption that fraudulent transactions may form their own distinct cluster. DBSCAN, on the other hand, identifies dense regions of data points, which can help uncover outliers representing potential fraud cases. By examining transactions that do not fit into normal clusters or have low density, these techniques aid in anomaly detection.
- Isolation Forests are another approach commonly used for outlier detection in unsupervised fraud detection. They work by constructing an ensemble of decision trees and isolating outliers by identifying how quickly they can be isolated during the tree-building process. Transactions that require fewer splits to be isolated are considered outliers. Isolation Forests are particularly effective at identifying rare and novel fraud patterns, making them suitable for adaptive fraud detection systems.
- One-class SVMs (Support Vector Machines) are designed for binary classification tasks where one class (in this case, normal transactions) is well-represented, and the other (fraudulent transactions) is underrepresented or poorly defined. These models learn to distinguish the normal class from the rest of the data, effectively creating a boundary that encapsulates normal transactions. Any data points falling outside this boundary are considered outliers and potential fraud cases.
Deep Learning and Neural Networks
Deep learning, a subset of machine learning, has gained significant attention in recent years for its effectiveness in various domains, including fraud detection. It involves training artificial neural networks to automatically learn and extract complex patterns from data, making it particularly well-suited for detecting sophisticated and evolving fraud schemes.
Neural network architectures such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have been applied to enhance fraud prevention. CNNs are primarily used for image and text data but can also be employed for detecting fraudulent patterns within transaction data, especially when visual representations of transactions are available. They excel at feature extraction through layers of convolution and pooling, allowing them to capture intricate details in data.
RNNs, on the other hand, are well-suited for processing sequential data. In the context of fraud detection, RNNs can analyze transaction sequences and identify irregular patterns that might be indicative of fraudulent activity. For example, they can identify unusual sequences of transactions or behaviors that deviate from a customer’s typical usage pattern, thus flagging potential fraud.
Deep learning models offer several advantages for fraud detection. They can automatically learn from vast amounts of data, making them adept at identifying complex and evolving fraud patterns that may be challenging to capture with traditional rule-based systems. Additionally, deep learning models can adapt to changing fraud tactics over time, providing a more proactive and dynamic approach to fraud prevention.
However, deep learning also presents challenges. One major issue is the need for large amounts of labeled training data, which can be scarce in fraud detection due to the rarity of fraudulent cases. Moreover, deep learning models are often considered “black boxes,” making it challenging to interpret their decision-making processes, which can be a concern when explaining why a transaction was flagged as fraudulent. Additionally, deep learning models can be computationally expensive and require substantial computing power.
Real-time Fraud Detection
In today’s fast-paced digital world, the need for real-time fraud detection systems has become paramount. Traditional batch processing methods, which analyze data periodically, are no longer sufficient to combat the rapidly evolving tactics of fraudsters. Real-time fraud detection is essential to identify and prevent fraudulent transactions as they occur, minimizing financial losses and protecting both businesses and consumers.
To achieve real-time fraud detection, organizations rely on stream processing and online learning techniques. Stream processing enables the continuous analysis of data as it flows in real-time, allowing for immediate detection of anomalies or suspicious patterns. Online learning techniques update fraud detection models dynamically as new data arrives, ensuring that the system adapts to emerging fraud tactics. This combination of stream processing and online learning enables organizations to stay ahead of fraudsters by swiftly identifying and mitigating fraudulent activity.
Future Trends and Challenges
Emerging Technologies: The future of fraud detection will be shaped by emerging technologies. Artificial intelligence (AI) and machine learning will continue to play a pivotal role, enabling more accurate and real-time fraud detection. Blockchain technology offers transparent and tamper-proof transaction records, enhancing fraud prevention in various industries. The Internet of Things (IoT) will introduce new data sources for fraud detection, as interconnected devices generate vast amounts of valuable information that can be leveraged to identify fraudulent activity.
Evolving Nature of Fraud: Fraudsters are becoming increasingly sophisticated and adaptable. They constantly evolve their tactics to exploit vulnerabilities in systems and processes. Future fraud detection systems must be capable of detecting novel and adaptive fraud schemes. Continuous monitoring, real-time analytics, and machine learning algorithms that can adapt to emerging threats will be crucial for staying ahead of fraudsters.
Ethical and Privacy Concerns: As fraud detection becomes more sophisticated, ethical considerations and privacy concerns become paramount. Striking the right balance between detecting fraud and protecting individuals’ privacy is a significant challenge. It’s essential to implement robust data governance and compliance frameworks to ensure that fraud detection methods respect privacy regulations and ethical standards. Building transparency into the decision-making process of fraud detection models will also be critical to gain public trust and address concerns related to algorithmic bias and discrimination.
Conclusion
In conclusion, the transformative power of machine learning in fraud detection cannot be overstated. It has revolutionized how businesses and organizations combat financial fraud by providing the tools to detect complex, evolving schemes in real-time. With techniques ranging from supervised learning to deep learning and the integration of emerging technologies like AI and blockchain, the landscape of fraud detection has evolved significantly.
However, fraud remains a persistent threat, with fraudsters continuously adapting and devising new tactics. The battle against fraud is ongoing and requires a proactive and dynamic approach. Technology will continue to play a pivotal role in this fight, enabling organizations to stay one step ahead of fraudsters and protect their financial assets and reputations. And machine learning in fraud detection is expected to bring positive results.
FAQs
How machine learning is used in fraud detection?
- Machine learning is employed in fraud detection by leveraging data, algorithms, and automation to identify and thwart fraudulent activities effectively.
- ML models analyze vast datasets of transactions, behaviors, and anomalies with precision, distinguishing between genuine and fraudulent activities.
- These models adapt over time, learning from new data and emerging threats, making them dynamic tools in the ongoing battle against fraud.
Which machine learning model to use for fraud detection?
- Several machine learning models are suitable for fraud detection, including Logistic Regression, Decision Trees, and Random Forests.
- Logistic Regression is often used as a baseline model for binary classification, distinguishing between legitimate and fraudulent transactions.
- Decision Trees create decision structures based on data features, while Random Forests combine multiple trees to address overfitting and handle imbalanced datasets.
What are the advantages of ML in fraud detection?
- Machine learning enhances fraud detection accuracy by analyzing intricate patterns, reducing false positives, and adapting to new threats over time.
- ML models are effective at identifying evolving and sophisticated fraud schemes that traditional rule-based systems may miss.
- These models provide a proactive and dynamic approach to fraud prevention, helping organizations stay ahead of fraudsters and protect their assets and reputation.
What are the challenges in fraud detection using machine learning?
- One major challenge is the need for a large amount of labeled training data, which can be scarce due to the rarity of fraudulent cases.
- Machine learning models can be considered “black boxes,” making it challenging to interpret their decision-making processes, which can be a concern for transparency and trust.
- The computational cost of deep learning models and the requirement for substantial computing power can pose challenges for some organizations.
What are the disadvantages of machine learning for fraud detection?
- Machine learning models are not a silver bullet and may still produce false positives or negatives, leading to potential financial losses or inefficiencies.
- There’s a continuous need to update and refine these models as fraud tactics evolve, which requires ongoing resources and expertise.
- Ethical concerns and privacy considerations must be addressed to strike the right balance between fraud detection and individual privacy, ensuring compliance with regulations and ethical standards.




 Guides
Guides News
News Blockchain
Blockchain Cryptocurrency
& Digital Assets
Cryptocurrency
& Digital Assets Web3
Web3 Metaverse & NFTs
Metaverse & NFTs
